101
术语 terminology
- 无限数据(Unbounded Data):一种不断增长的,基本上无限的数据集。这些通常被称为流式数据(Streaming data)。
- 流式计算引擎:为了计算无尽的数据而设计的计算引擎
- 无界数据处理(Unbounded data processing):持续地处理上面提到的无尽的数据。批量系统可以通过重复运行来处理无界数据。
批量和流式的区别 batch versus streaming
流式计算演变
Lambda 架构
流式计算需要做到:
- 正确性/一致性:流式计算系统需要不断地持久化(checkpoint)状态(persistent state),并且这套机制必须经过精心设计,足以在机器故障的情况下保持一致性。
- 支持面向时间的计算:面向时间的计算是批量给不了的。源源不断从网络流过来的数据是有时间偏差的,现有的批量系统是不能处理这种时间上带来的复杂读。
才能够和批量想提并论甚至超越批量计算
数据处理模式 data processing petterns
有界数据 MapReduce 处理
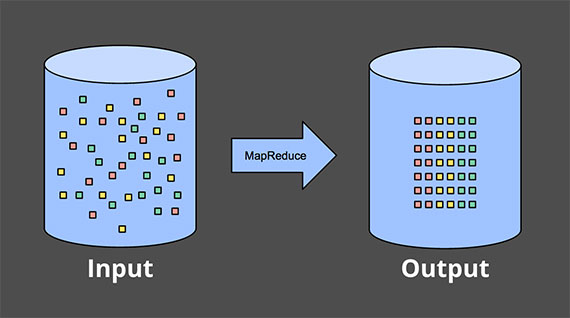
无限数据 - 批量处理
将输入数据切割成固定大小的窗口,然后将每个窗口作为单独的有界的数据进行处理。
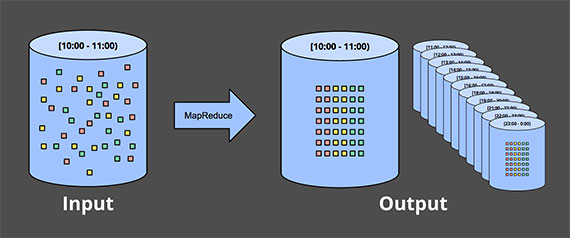
问题:
- 数据可能被「随机」地分配到错误的基于事件事件的窗口
- 不能解决更复杂的窗口策略,比如会话。会话通常被定义为一个用户的一段持续的活动,通过超过一定的时间阈值没有操作,会终结前一段会话。
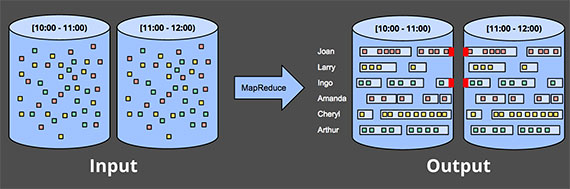
无限数据 - 流式计算
无限数据处理方法:
- 时间无关的计算 Time-agnostic
- 近似计算 Approximation
- 基于处理时间的窗口计算 Windowing by processing time
- 基于事件时间的窗口计算 Windowing by event time
时间无关 Time-agnostic
过滤 filtering
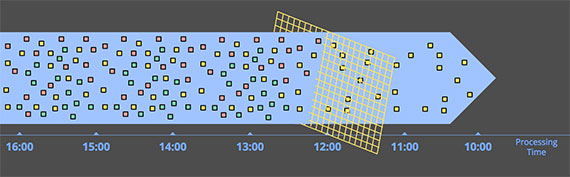
过滤无界数据,从不同类型的数据集合被过滤成包含单一类型的同类集合。在任何时候都只依赖于单条数据,因此数据是否无限、是否无序、事件时间偏差都不需要考虑。
內联
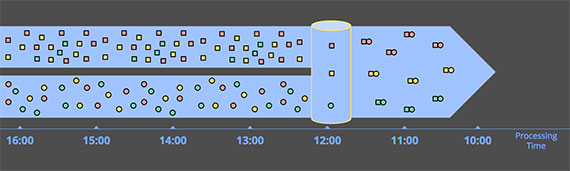
当从 2 个无界数据源分别收到一条数据就把它们关联起来,没有任何时间方面的考虑。
近似算法
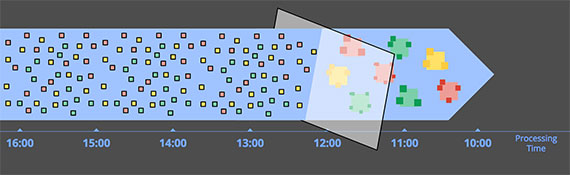
窗口
窗口化就是按照时间边界把有限的或者无限的数据切割成有限的块来进行处理。
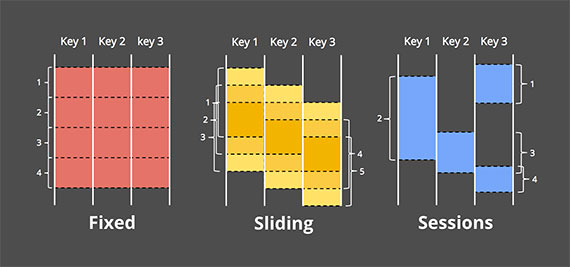
- 固定窗口(Fixed windows):把数据按照固定大小的时间段切割。
- 滑动窗口(Sliding windows):固定窗口的泛化,滑动窗口由固定长度和固定步长来决定。如果步长小于长度,则窗口重叠。如果步长等于长度,则退化为固定窗口。如果步长大于长度,则可以视为采样窗口。
- 会话(Sessions):动态窗口的典范,会话由一系列持续的事件组成,窗口之间由不活动的间隙分隔。
按处理时间进行窗口化(Windowing by processing time)
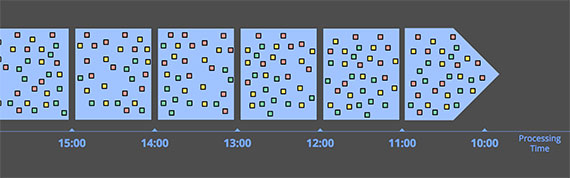
当按处理时间窗口化时,系统基本上将输入数据塞到当前窗口中,直到处理时间到了定义窗口的边界。例如,在 5 分钟固定窗口的情况下,系统会将数据缓冲 5 分钟,之后它会将这 5 分钟内观察到的所有数据一并处理发送打下游。
按处理时间窗口化,不需要关心事件时间,因此其不用操心延迟、乱序数据,其实现非常简单。
但是其适用场景很有限:
- 完全不关心事件事件的处理场景
- 关心事件时间,且要求基于处理时间的窗口要反映实际上这些事件的实际情况,则要求事件必须按事件时间顺序有序的到达系统
按事件时间进行窗口化(Windowing by processing time)
按照事件发生的时间边界切割数据才符合真实需求。
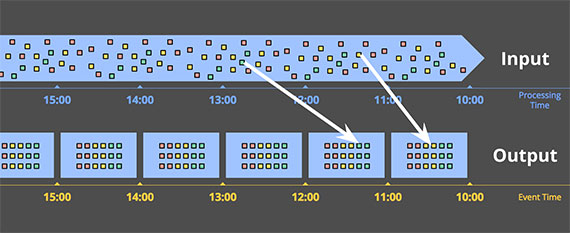
按照事件时间将数据切割到固定窗口。
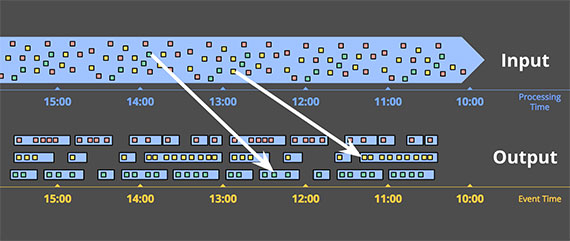
基于事件时间切割窗口的另一个好处是,可以创建动态大小的窗口,例如会话窗口,避免了将一个会话因为基于处理时间而拆开。
基于事件时间的窗口实现有 2 个显著的缺点:
- 缓冲:需要更多的数据缓冲
- 窗口完整性:如何确定已经得到当前窗口的所有数据?事实上,我们根本做不到。