发布工程
为保障服务的可靠部署与变更需要制定可靠的发布流程,为此 SRE 需要保证二进制文件和配置文件是以一种可重现的、自动化的方式构建出来的
关注从源代码到部署的整个流程:
- 软件如何存储于源代码仓库
- 构建时如何编译
- 如何测试、打包,最终进行部署
需要掌握的能力:
- 源代码管理、编译器、构建配置语言、自动化构建工具、包管理器、安装器
- 开发、配置管理、测试集成、系统管理、甚至用户支持
发布工程哲学
1. 自服务模型
研发团队自己掌握和执行自己的发布流程
发布工程师开发工具,制定最佳实践,使得整个发布过程自动化到基本不需要工程师干预
2. 追求速度
频繁地重新构建面向用户的软件组件
优点:
- 用户可见的功能应该尽快上线
- 使得软件的每个版本之间的变更减少
方式:
- 定时构建,基于测试结果和包含的功能在所有可用的构建版本中选择某个版本进行发布
- 测试通过即发布
3. 密闭性
构建工具必须确保一致性与可重复性
构建过程密闭:指定版本的构建工具和依赖库
4. 强调策略和流程
多层安全和访问控制机制确保发布过程中只有指定的人才能执行指定的操作
- 批准源代码改动
- 指定发布流程中需要执行的动作
- 创建新的发布版本
- 批准初始的集成请求
- 实践部署某个发布版本
- 修改某个项目的构建配置文件
持续构建与部署
使用 CI/CD 工具,构造一条优化的发布部署流水线和发布部署策略
- 代码管理和审查的相应流程
- 完善的自动化测试
只需在本地发起一个 git 提交,剩下的单元测试,打包构建,代码部署功能全部自动化完成,让持续集成,持续交付,持续部署变得简单以操作,真正解决人工构建部署的诸多问题。
1. 构建
定义构建目标,每个目标的依赖关系,进行具体构建时可用自动进行
构建结果支持查看其构建时间、构建源代码版本、构建的标识符,使得其与构建过程对应
2. 分支管理
单主干 (Trunk-based development)
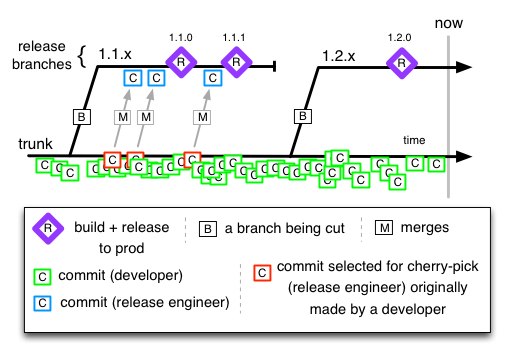
- 所有团队成员在主分支进行开发
- 发布时基于主分支创建发布分支
- bug 修复在主分支中进行,再 cherry-pick 到发布分支
避免在第一次构建之后,在引入主分支上的其他无关改动,明确每个发布版本中包含的全部改动
What is trunk based development
GitHub flow
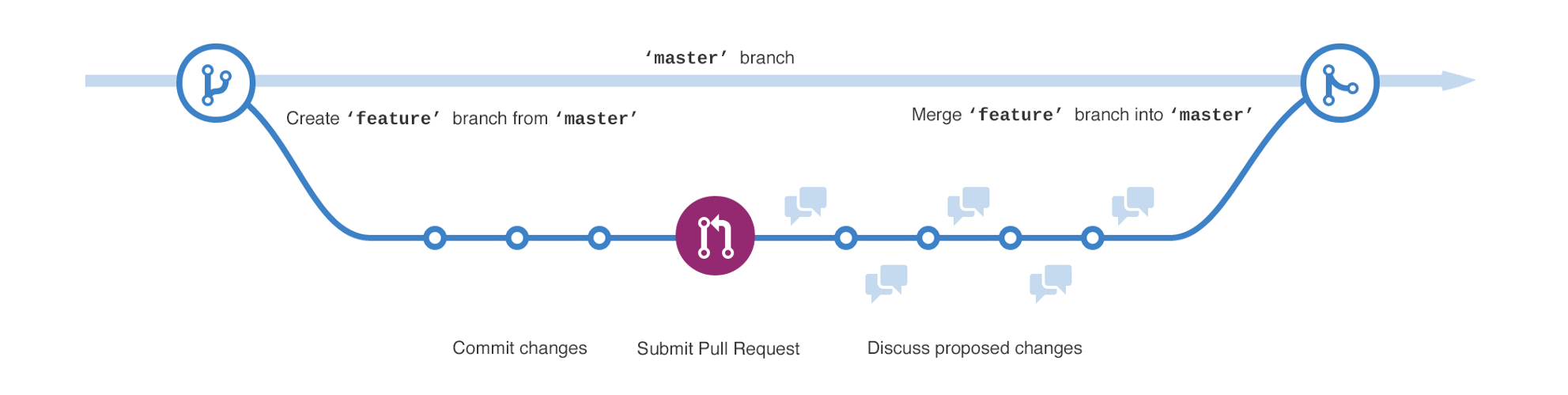
- master 分支中包含稳定的代码,该分支已经或即将被部署到生产环境
- 对代码的任何修改,包括 bug 修复,hotfix,新功能开发等都在单独的分支进行,当需要进行修改时,从 master 分支创建一个新的分支,分支的名称应该简单清晰的描述该分支的作用
- 当分支代码全部完成后,通过 GitHub 提交新的 pull request,团队其他人员对代码进行审查,提出修改意见,由持续集成服务器(如 Jenkins) 对新分支进行自动化测试,再从 master 分支部署到生产环境
git-flow
git-flow 围绕的核心概念是版本发布 (release), 适用于有较长版本发布周期的项目
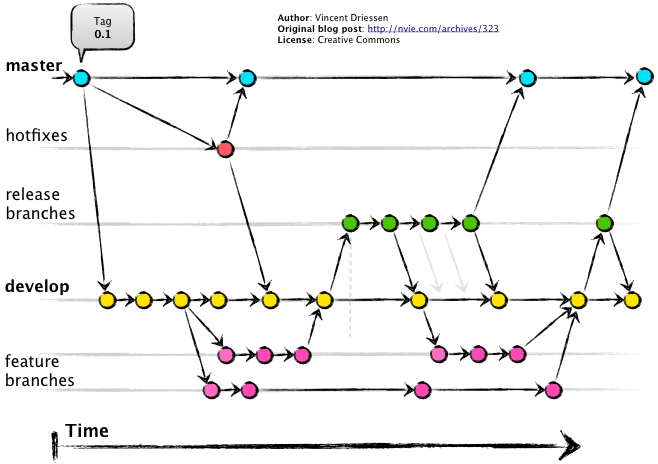
- master: 可部署到生产环境的代码
- develop: 下一个版本需要发布的内容(是一个进行代码集成的分支,当 develop 分支集成了足够的新功能和 bug 修复代码后,通过一个发布流程来完成新版本的发布,发布完成之后,将 develop 分支合并到 master 分支中)
| 分支类型 | 命名规范 | 创建自 | 合并到 | 说明 |
|---|---|---|---|---|
| feature | feature/* | develop | develop | 新功能 |
| release | release/* | develop | develop 和 master | 一次新版本的发布 |
| hotfix | hotfix/* | master | develop 和 master | 生产环境中发现的紧急 bug 的修复 |
- feature: 开发一个新的功能
- 从 develop 分支创建一个新的 feature 分支,如 feature/my-awesome-feature。
- 在该 feature 分支上进行开发,提交代码,push 到远端仓库。
- 当代码完成之后,合并到 develop 分支并删除当前 feature 分支。
- release:发布分支
- hotfix:线上代码 bug 修复
a-successful-git-branching-model
3. 持续测试
持续测试系统会在每个主分支改动提交之后运行单元测试
快速检测构建错误和测试错误
使用项目中定义个构建目标及测试目标的执行结果来决定是否发布某个版本
使用最后一个测试全部通过的软件版本进行最新的发布
在发布过程中,也要对发布分支重新进行全部单元测试
3. 打包
- 使用名称与构建 ID 标签唯一识别一个包
- 记录构建结果的哈希值,并加入签名确保完整性
4. 代码部署
5. 配置管理
配置管理是不稳定性的一个重要来源
将配置文件存放于代码仓库中,同时进行严格的代码评审
- 使用主分支版本配置文件:开发者和 SRE 可用同时修改主分支上的配置文件,这些修改经过代码评审之后会应用到正在运行的系统上
- 易于理解和执行
- 容易造成提交的版本和实际运行的配置文件不一致
- 将配置文件与二进制文件打包在同一个包中
- 适用于配置少或每次发布都会更改配置的项目
- 简化部署
- 将配置文件打包:利用构建打包系统来分发配置文件,像二进制文件一样,利用构建 ID 来重新构建每一时刻的配置文件
- 从外部存储服务中读取配置文件
简单化
- 软件系统是动态和不稳定的
- 软件的简单性是可靠性的前提条件
No code is the best way to write secure and reliable applications. Write nothing; deploy nowhere.
稳定性与灵活性
对大多数生产环境软件系统来说,我们想要再稳定性和灵活性上保持平衡
- SRE 通过创建流程、实践以及工具,来提高软件的可靠性(可靠的流程也会提高研发的灵活性)
- SRE 需要最小化这些流程于工具对于开发人员的灵活性造成的影响
最小化意外复杂度
我们希望程序按设计执行,可以预见性地完成商业目标,生产环境中的意外时 SRE 最大的敌人
关注必要复杂度和意外复杂度之间的区别非常关键: 必要复杂度时一个给定的情况所固有的复杂度,不能从该问题的定义中移除,而意外复杂度则是不固定的,可以通过工程上的努力来解决。
- 在他们所负责的系统中引入意外复杂度时,及时提出抗议
- 不断地努力消除正在接手的和已经负责运维的系统的复杂度
去除多余的代码
工程师经常对自己编写的代码形成一种情感依附,不愿将无用的代码移除,
某种程度上,每一行新代码都是服务稳定运行的负担,SRE 推崇保证所有的代码都有必须存在目的,审查代码以确保它确实符合商业目标,定期删除无用代码,并且在各级测试中增加代码膨胀检测
「软件膨胀」用来描述软件随实践的推移不停地增加新功能而变得更慢和更大的趋势,添加到项目中的每行代码都可能引入新的缺陷和错误,
最小 API
不是在不能添加更多的时候,而是没有什么可以去掉的时候,才能达到完美
书写一个明确的、最小的 API 是管理软件系统管理简单性必要的部分。
模块化
对系统中的某个部分进行隔离式的变更的能力对创建一个可以运维的系统来说非常必要
发布的简单化
- 发布时按小的批次进行的,易于理解每次变更贵系统的影响(测量和理解单一变化的影响要比同时应对一系列变化更加容易)
- 通过每次进展一点,同时考虑每次改变对系统的改善和退化来寻找最佳方案